GraphQL
Getting Started
Helpful Resources
General resources:
GraphQL at GitLab:
- GitLab Unfiltered GraphQL playlist
-
GraphQL at GitLab: Deep Dive (video) by Nick Thomas
- An overview of the history of GraphQL at GitLab (not frontend-specific)
-
GitLab Feature Walkthrough with GraphQL and Vue Apollo (video) by Natalia Tepluhina
- A real-life example of implementing a frontend feature in GitLab using GraphQL
- History of client-side GraphQL at GitLab (video) Illya Klymov and Natalia Tepluhina
-
From Vuex to Apollo (video) by Natalia Tepluhina
- An overview of when Apollo might be a better choice than Vuex, and how one could go about the transition
-
🛠️ Vuex -> Apollo Migration: a proof-of-concept project- A collection of examples that show the possible approaches for state management with Vue+GraphQL+(Vuex or Apollo) apps
Libraries
We use Apollo (specifically Apollo Client) and Vue Apollo when using GraphQL for frontend development.
If you are using GraphQL in a Vue application, the Usage in Vue section can help you learn how to integrate Vue Apollo.
For other use cases, check out the Usage outside of Vue section.
We use Immer for immutable cache updates; see Immutability and cache updates for more information.
Tooling
Apollo GraphQL VS Code extension
If you use VS Code, the Apollo GraphQL extension supports autocompletion in .graphql files. To set up
the GraphQL extension, follow these steps:
-
Generate the schema:
bundle exec rake gitlab:graphql:schema:dump -
Add an
apollo.config.jsfile to the root of yourgitlablocal directory. -
Populate the file with the following content:
module.exports = { client: { includes: ['./app/assets/javascripts/**/*.graphql', './ee/app/assets/javascripts/**/*.graphql'], service: { name: 'GitLab', localSchemaFile: './tmp/tests/graphql/gitlab_schema.graphql', }, }, }; -
Restart VS Code.
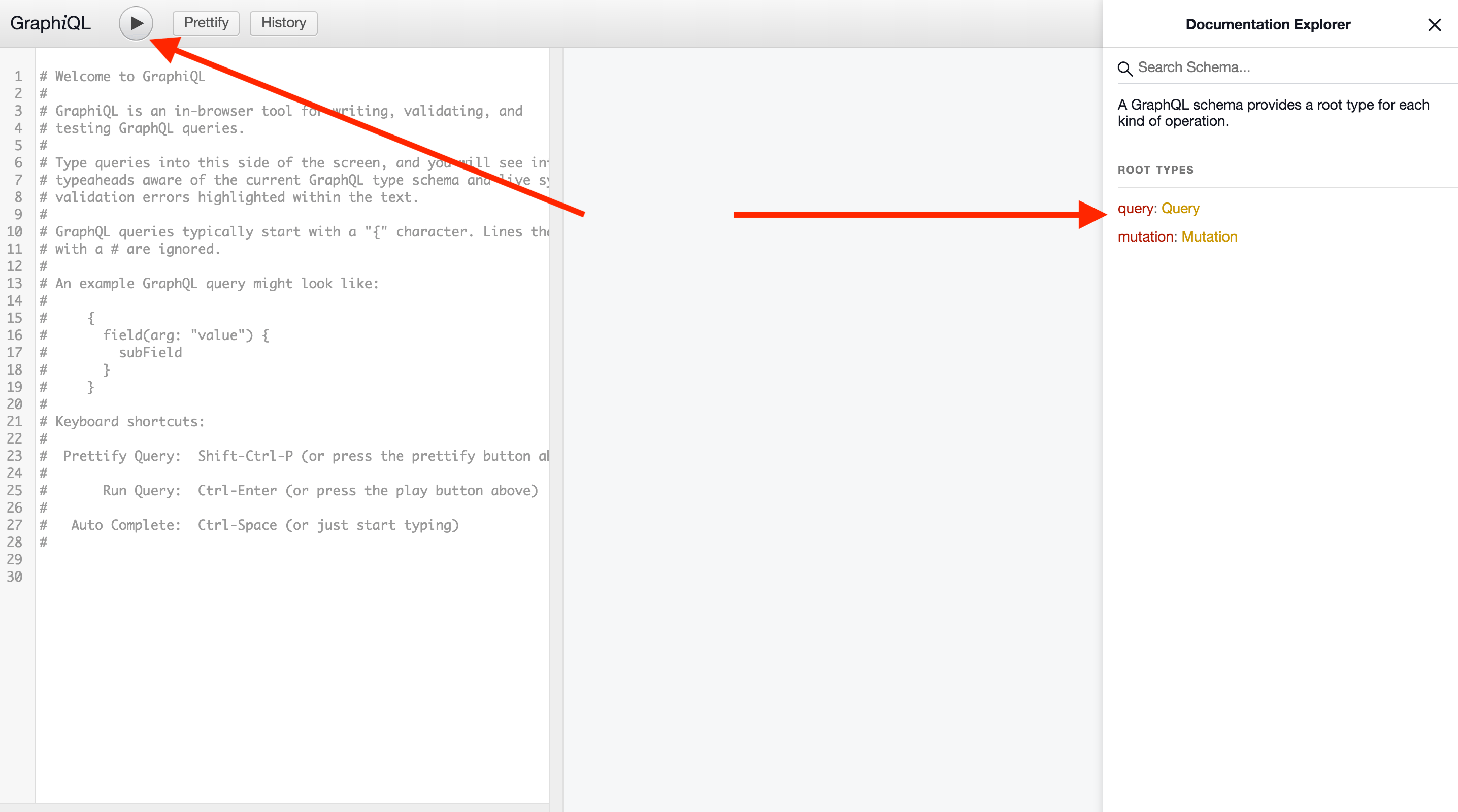
Exploring the GraphQL API
Our GraphQL API can be explored via GraphiQL at your instance's
/-/graphql-explorer or at GitLab.com. Consult the
GitLab GraphQL API Reference documentation
where needed.
To check all existing queries and mutations, on the right side of GraphiQL, select Documentation explorer. To check the execution of the queries and mutations you've written, in the upper-left corner, select Execute query.
Apollo Client
To save duplicated clients getting created in different apps, we have a default client that should be used. This sets up the Apollo client with the correct URL and also sets the CSRF headers.
Default client accepts two parameters: resolvers and config.
-
resolversparameter is created to accept an object of resolvers for local state management queries and mutations -
configparameter takes an object of configuration settings:-
cacheConfigfield accepts an optional object of settings to customize Apollo cache -
baseUrlallows us to pass a URL for GraphQL endpoint different from our main endpoint (for example,${gon.relative_url_root}/api/graphql) -
fetchPolicydetermines how you want your component to interact with the Apollo cache. Defaults to "cache-first".
-
Multiple client queries for the same object
If you are making multiple queries to the same Apollo client object you might encounter the following error: Cache data may be lost when replacing the someProperty field of a Query object. To address this problem, either ensure all objects of SomeEntityhave an id or a custom merge function. We are already checking id presence for every GraphQL type that has an id, so this shouldn't be the case (unless you see this warning when running unit tests; in this case ensure your mocked responses contain an id whenever it's requested).
When SomeEntity type doesn't have an id property in the GraphQL schema, to fix this warning we need to define a custom merge function.
We have some client-wide types with merge: true defined in the default client as typePolicies (this means that Apollo will merge existing and incoming responses in the case of subsequent queries). Consider adding SomeEntity there or defining a custom merge function for it.
GraphQL Queries
To save query compilation at runtime, webpack can directly import .graphql
files. This allows webpack to pre-process the query at compile time instead
of the client doing compilation of queries.
To distinguish queries from mutations and fragments, the following naming convention is recommended:
-
all_users.query.graphqlfor queries; -
add_user.mutation.graphqlfor mutations; -
basic_user.fragment.graphqlfor fragments.
If you are using queries for the CustomersDot GraphQL endpoint, end the filename with .customer.query.graphql, .customer.mutation.graphql, or .customer.fragment.graphql.
Fragments
Fragments are a way to make your complex GraphQL queries more readable and re-usable. Here is an example of GraphQL fragment:
fragment DesignListItem on Design {
id
image
event
filename
notesCount
}Fragments can be stored in separate files, imported and used in queries, mutations, or other fragments.
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}More about fragments: GraphQL documentation
Global IDs
The GitLab GraphQL API expresses id fields as Global IDs rather than the PostgreSQL
primary key id. Global ID is a convention
used for caching and fetching in client-side libraries.
To convert a Global ID to the primary key id, you can use getIdFromGraphQLId:
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);It is required to query global id for every GraphQL type that has an id in the schema:
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}Skip query with async variables
Whenever a query has one or more variable that requires another query to have executed before it can run, it is vital to add a skip() property to the query with all relations.
Failing to do so will result in the query executing twice: once with the default value (whatever was defined on the data property or undefined) and once more once the initial query is resolved, triggering a new variable value to be injected in the smart query and then refetched by Apollo.
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}Splitting queries in GraphQL
Splitting queries in Apollo is often done to optimize data fetching by breaking down larger, monolithic queries into smaller, more manageable pieces.
Why split queries in GraphQL
- Increased query complexity We have limits for GraphQL queries which should be adhered to.
- Performance Smaller, targeted queries often result in faster response times from the server, which directly benefits the frontend by getting data to the client sooner.
- Better Component Decoupling and Maintainability Each component can handle its own data needs, making it easier to reuse components across your app without requiring access to a large, shared query.
How to split queries
- Define multiple queries and use them independently in various parts of your component hierarchy. This way, each component fetches only the data it needs.
If you look at work item query architecture , we have split the queries for most of the widgets for the same reason of query complexity and splitting of concerned data.
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}- Conditional Queries Using the
@includeand@skipDirectives
Apollo supports conditional queries using these directives, allowing you to split queries based on a component's state or other conditions
query projectWorkItems(
$searchTerm: String
$fullPath: ID!
$types: [IssueType!]
$in: [IssuableSearchableField!]
$iid: String = null
$searchByIid: Boolean = false
$searchByText: Boolean = true
) {
workspace: project(fullPath: $fullPath) {
id
workItems(search: $searchTerm, types: $types, in: $in) @include(if: $searchByText) {
nodes {
...
}
}
workItemsByIid: workItems(iid: $iid, types: $types) @include(if: $searchByIid) {
nodes {
...
}
}
}
}#import "../fragments/user.fragment.graphql"
#import "~/graphql_shared/fragments/user_availability.fragment.graphql"
query workspaceAutocompleteUsersSearch(
$search: String!
$fullPath: ID!
$isProject: Boolean = true
) {
groupWorkspace: group(fullPath: $fullPath) @skip(if: $isProject) {
id
users: autocompleteUsers(search: $search) {
...
}
}
workspace: project(fullPath: $fullPath) {
id
users: autocompleteUsers(search: $search) {
...
}
}
}CAUTION We have to be careful to make sure that we do not invalidate the existing GraphQL queries when we split queries. We should ensure to check the inspector that the same quries are not called multiple times when we split queries.
Immutability and cache updates
From Apollo version 3.0.0 all the cache updates need to be immutable. It needs to be replaced entirely with a new and updated object.
To facilitate the process of updating the cache and returning the new object we use the library Immer. Follow these conventions:
- The updated cache is named
data. - The original cache data is named
sourceData.
A typical update process looks like this:
...
const sourceData = client.readQuery({ query });
const data = produce(sourceData, draftState => {
draftState.commits.push(newCommit);
});
client.writeQuery({
query,
data,
});
...As shown in the code example by using produce, we can perform any kind of direct manipulation of the
draftState. Besides, immer guarantees that a new state which includes the changes to draftState is generated.
Usage in Vue
To use Vue Apollo, import the Vue Apollo plugin as well as the default client. This should be created at the same point the Vue application is mounted.
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```0
Read more about [Vue Apollo](https://github.com/vuejs/vue-apollo) in the [Vue Apollo documentation](https://vue-apollo.netlify.app/guide/).
### Local state with Apollo
It is possible to manage an application state with Apollo when creating your default client.
#### Using client-side resolvers
The default state can be set by writing to the cache after setting up the default client. In the
example below, we are using query with `@client` Apollo directive to write the initial data to
Apollo cache and then get this state in the Vue component:
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```1
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```2
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```3
Instead of using `writeQuery`, we can create a type policy that will return `user` on every attempt of reading the `userQuery` from the cache:
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```4
Along with creating local data, we can also extend existing GraphQL types with `@client` fields. This is extremely helpful when we need to mock an API response for fields not yet added to our GraphQL API.
##### Mocking API response with local Apollo cache
Using local Apollo Cache is helpful when we have a reason to mock some GraphQL API responses, queries, or mutations locally (such as when they're still not added to our actual API).
For example, we have a [fragment](#fragments) on `DesignVersion` used in our queries:
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```5
We also must fetch the version author and the `created at` property to display in the versions dropdown list. But, these changes are still not implemented in our API. We can change the existing fragment to get a mocked response for these new fields:
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```6
Now Apollo tries to find a _resolver_ for every field marked with `@client` directive. Let's create a resolver for `DesignVersion` type (why `DesignVersion`? because our fragment was created on this type).
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```7
We need to pass a resolvers object to our existing Apollo Client:
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```8
For each attempt to fetch a version, our client fetches `id` and `sha` from the remote API endpoint. It then assigns our hardcoded values to the `author` and `createdAt` version properties. With this data, frontend developers are able to work on their UI without being blocked by backend. When the response is added to the API, our custom local resolver can be removed. The only change to the query/fragment is to remove the `@client` directive.
Read more about local state management with Apollo in the [Vue Apollo documentation](https://vue-apollo.netlify.app/guide/local-state.html#local-state).
### Using with Pinia
Combining [Pinia](pinia.md) and Apollo in a single Vue application is generally discouraged.
[Learn about the restrictions and circumstances around combining Apollo and Pinia](state_management.md#combining-pinia-and-apollo).
### Using with Vuex
We do not recommend combining Vuex and Apollo Client. [Vuex is deprecated in GitLab](vuex.md#deprecated).
If you have an existing Vuex store that's used alongside Apollo we strongly recommend [migrating away from Vuex entirely](migrating_from_vuex.md).
[Learn more about state management in GitLab](state_management.md).
### Working on GraphQL-based features when frontend and backend are not in sync
Any feature that requires GraphQL queries/mutations to be created or updated should be carefully
planned. Frontend and backend counterparts should agree on a schema that satisfies both client-side and
server-side requirements. This enables both departments to start implementing their parts without
blocking each other.
Ideally, the backend implementation should be done prior to the frontend so that the client can
immediately start querying the API with minimal back and forth between departments. However, we
recognize that priorities don't always align. For the sake of iteration and
delivering work we're committed to, it might be necessary for the frontend to be implemented ahead
of the backend.
#### Implementing frontend queries and mutations ahead of the backend
In such case, the frontend defines GraphQL schemas or fields that do not correspond to any
backend resolver yet. This is fine as long as the implementation is properly feature-flagged so it
does not translate to public-facing errors in the product. However, we do validate client-side
queries/mutations against the backend GraphQL schema with the `graphql-verify` CI job.
You must confirm your changes pass the validation if they are to be merged before the
backend actually supports them. Below are a few suggestions to go about this.
##### Using the `@client` directive
The preferred approach is to use the `@client` directive on any new query, mutation, or field that
isn't yet supported by the backend. Any entity with the directive is skipped by the
`graphql-verify` validation job.
Additionally Apollo attempts to resolve them client-side, which can be used in conjunction with
[Mocking API response with local Apollo cache](#mocking-api-response-with-local-apollo-cache). This
provides a convenient way of testing your feature with fake data defined client-side.
When opening a merge request for your changes, it can be a good idea to provide local resolvers as a
patch that reviewers can apply in their GDK to easily smoke-test your work.
Make sure to track the removal of the directive in a follow-up issue, or as part of the backend
implementation plan.
##### Adding an exception to the list of known failures
GraphQL queries/mutations validation can be completely turned off for specific files by adding their
paths to the
[`config/known_invalid_graphql_queries.yml`](https://gitlab.com/gitlab-org/gitlab/-/blob/master/config/known_invalid_graphql_queries.yml)
file, much like you would disable ESLint for some files via an `.eslintignore` file.
Bear in mind that any file listed in here is not validated at all. So if you're only adding
fields to an existing query, use the `@client` directive approach so that the rest of the query
is still validated.
Again, make sure that those overrides are as short-lived as possible by tracking their removal in
the appropriate issue.
#### Feature-flagged queries
In cases where the backend is complete and the frontend is being implemented behind a feature flag,
a couple options are available to leverage the feature flag in the GraphQL queries.
##### The `@include` directive
The `@include` (or its opposite, `@skip`) can be used to control whether an entity should be
included in the query. If the `@include` directive evaluates to `false`, the entity's resolver is
not hit and the entity is excluded from the response. For example:
```javascript
#import "./design_list.fragment.graphql"
#import "./diff_refs.fragment.graphql"
fragment DesignItem on Design {
...DesignListItem
fullPath
diffRefs {
...DesignDiffRefs
}
}
```9
Then in the Vue (or JavaScript) call to the query we can pass in our feature flag. This feature
flag needs to be already set up correctly. See the [feature flag documentation](../feature_flags/index.md)
for the correct way to do this.
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```0
Note that, even if the directive evaluates to `false`, the guarded entity is sent to the backend and
matched against the GraphQL schema. So this approach requires that the feature-flagged entity
exists in the schema, even if the feature flag is disabled. When the feature flag is turned off, it
is recommended that the resolver returns `null` at the very least using the same feature flag as the frontend. See the [API GraphQL guide](../api_graphql_styleguide.md#feature-flags).
##### Different versions of a query
There's another approach that involves duplicating the standard query, and it should be avoided. The copy includes the new entities
while the original remains unchanged. It is up to the production code to trigger the right query
based on the feature flag's status. For example:
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```1
##### Avoiding multiple query versions
The multiple version approach is not recommended as it results in bigger merge requests and requires maintaining
two similar queries for as long as the feature flag exists. Multiple versions can be used in cases where the new
GraphQL entities are not yet part of the schema, or if they are feature-flagged at the schema level
(`new_entity: :feature_flag`).
### Manually triggering queries
Queries on a component's `apollo` property are made automatically when the component is created.
Some components instead want the network request made on-demand, for example a dropdown list with lazy-loaded items.
There are two ways to do this:
1. Use the `skip` property
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```2
1. Using `addSmartQuery`
You can manually create the Smart Query in your method.
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```3
### Working with pagination
The GitLab GraphQL API uses [Relay-style cursor pagination](https://www.apollographql.com/docs/react/pagination/overview/#cursor-based)
for connection types. This means a "cursor" is used to keep track of where in the data
set the next items should be fetched from. [GraphQL Ruby Connection Concepts](https://graphql-ruby.org/pagination/connection_concepts.html)
is a good overview and introduction to connections.
Every connection type (for example, `DesignConnection` and `DiscussionConnection`) has a field `pageInfo` that contains an information required for pagination:
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```4
Here:
- `startCursor` displays the cursor of the first items and `endCursor` displays the cursor of the last items.
- `hasPreviousPage` and `hasNextPage` allow us to check if there are more pages
available before or after the current page.
When we fetch data with a connection type, we can pass cursor as `after` or `before`
parameter, indicating a starting or ending point of our pagination. They should be
followed with `first` or `last` parameter respectively to indicate _how many_ items
we want to fetch after or before a given endpoint.
For example, here we're fetching 10 designs after a cursor (let us call this `projectQuery`):
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```5
Note that we are using the [`page_info.fragment.graphql`](https://gitlab.com/gitlab-org/gitlab/-/blob/master/app/assets/javascripts/graphql_shared/fragments/page_info.fragment.graphql) to populate the `pageInfo` information.
#### Using `fetchMore` method in components
This approach makes sense to use with user-handled pagination. For example, when the scrolling to fetch more data or explicitly clicking a **Next Page** button.
When we need to fetch all the data initially, it is recommended to use [a (non-smart) query, instead](#using-a-recursive-query-in-components).
When making an initial fetch, we usually want to start a pagination from the beginning.
In this case, we can either:
- Skip passing a cursor.
- Pass `null` explicitly to `after`.
After data is fetched, we can use the `update`-hook as an opportunity
[to customize the data that is set in the Vue component property](https://apollo.vuejs.org/api/smart-query.html#options).
This allows us to get a hold of the `pageInfo` object among other data.
In the `result`-hook, we can inspect the `pageInfo` object to see if we need to fetch
the next page. Note that we also keep a `requestCount` to ensure that the application
does not keep requesting the next page, indefinitely:
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```6
When we want to move to the next page, we use an Apollo `fetchMore` method, passing a
new cursor (and, optionally, new variables) there.
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```7
##### Defining field merge policy
We would also need to define a field policy to specify how do we want to merge the existing results with the incoming results. For example, if we have `Previous/Next` buttons, it makes sense to replace the existing result with the incoming one:
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```8
When we have an infinite scroll, it would make sense to add the incoming `designs` nodes to existing ones instead of replacing. In this case, merge function would be slightly different:
```javascript
import { getIdFromGraphQLId } from '~/graphql_shared/utils';
const primaryKeyId = getIdFromGraphQLId(data.id);
```9
`apollo-client` [provides](https://github.com/apollographql/apollo-client/blob/212b1e686359a3489b48d7e5d38a256312f81fde/src/utilities/policies/pagination.ts)
a few field policies to be used with paginated queries. Here's another way to achieve infinite
scroll pagination with the `concatPagination` policy:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```0
This is similar to the `DesignCollection` example above as new page results are appended to the
previous ones.
For some cases, it's hard to define the correct `keyArgs` for the field because all
the fields are updated. In this case, we can set `keyArgs` to `false`. This instructs
Apollo Client to not perform any automatic merge, and fully rely on the logic we
put into the `merge` function.
For example, we have a query like this:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```1
Here, the `groups` field doesn't have a good candidate for `keyArgs`: we don't want to account for `after` argument because it will change on requesting subsequent pages. Setting `keyArgs` to `false` makes the update work as intended:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```2
#### Using a recursive query in components
When it is necessary to fetch all paginated data initially an Apollo query can do the trick for us.
If we need to fetch the next page based on user interactions, it is recommend to use a [`smartQuery`](https://apollo.vuejs.org/api/smart-query.html) along with the [`fetchMore`-hook](#using-fetchmore-method-in-components).
When the query resolves we can update the component data and inspect the `pageInfo` object. This allows us
to see if we need to fetch the next page, calling the method recursively.
Note that we also keep a `requestCount` to ensure that the application does not keep
requesting the next page, indefinitely.
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```3
#### Pagination and optimistic updates
When Apollo caches paginated data client-side, it includes `pageInfo` variables in the cache key.
If you wanted to optimistically update that data, you'd have to provide `pageInfo` variables
when interacting with the cache via [`.readQuery()`](https://www.apollographql.com/docs/react/v2/api/apollo-client/#ApolloClient.readQuery)
or [`.writeQuery()`](https://www.apollographql.com/docs/react/v2/api/apollo-client/#ApolloClient.writeQuery).
This can be tedious and counter-intuitive.
To make it easier to deal with cached paginated queries, Apollo provides the `@connection` directive.
The directive accepts a `key` parameter that is used as a static key when caching the data.
You'd then be able to retrieve the data without providing any pagination-specific variables.
Here's an example of a query using the `@connection` directive:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```4
In this example, Apollo stores the data with the stable `dastSiteProfiles` cache key.
To retrieve that data from the cache, you'd then only need to provide the `$fullPath` variable,
omitting pagination-specific variables like `after` or `before`:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```5
Read more about the `@connection` directive in [Apollo's documentation](https://www.apollographql.com/docs/react/caching/advanced-topics/#the-connection-directive).
### Batching similar queries
By default, the Apollo client sends one HTTP request from the browser per query. You can choose to
batch several queries in a single outgoing request and lower the number of requests by defining a
[batchKey](https://www.apollographql.com/docs/react/api/link/apollo-link-batch-http/#batchkey).
This can be helpful when a query is called multiple times from the same component but you
want to update the UI once. In this example we use the component name as the key:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```6
The batch key can be the name of the component.
#### Polling and Performance
While the Apollo client has support for simple polling, for performance reasons, our [ETag-based caching](../polling.md) is preferred to hitting the database each time.
After the ETag resource is set up to be cached from backend, there are a few changes to make on the frontend.
First, get your ETag resource from the backend, which should be in the form of a URL path. In the example of the pipelines graph, this is called the `graphql_resource_etag`, which is used to create new headers to add to the Apollo context:
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```7
Here, the apollo query is watching for changes in `graphqlResourceEtag`. If your ETag resource dynamically changes, you should make sure the resource you are sending in the query headers is also updated. To do this, you can store and update the ETag resource dynamically in the local cache.
You can see an example of this in the pipeline status of the pipeline editor. The pipeline editor watches for changes in the latest pipeline. When the user creates a new commit, we update the pipeline query to poll for changes in the new pipeline.
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```8
```javascript
query allReleases(...) {
project(...) {
id // Project has an ID in GraphQL schema so should fetch it
releases(...) {
nodes {
// Release has no ID property in GraphQL schema
name
tagName
tagPath
assets {
count
links {
nodes {
id // Link has an ID in GraphQL schema so should fetch it
name
}
}
}
}
pageInfo {
// PageInfo no ID property in GraphQL schema
startCursor
hasPreviousPage
hasNextPage
endCursor
}
}
}
}
```9
Finally, we can add a visibility check so that the component pauses polling when the browser tab is not active. This should lessen the request load on the page.
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```0
You can use [this MR](https://gitlab.com/gitlab-org/gitlab/-/merge_requests/59672/) as a reference on how to fully implement ETag caching on the frontend.
Once subscriptions are mature, this process can be replaced by using them and we can remove the separate link library and return to batching queries.
##### How to test ETag caching
You can test that your implementation works by checking requests on the network tab. If there are no changes in your ETag resource, all polled requests should:
- Be `GET` requests instead of `POST` requests.
- Have an HTTP status of `304` instead of `200`.
Make sure that caching is not disabled in your developer tools when testing.
If you are using Chrome and keep seeing `200` HTTP status codes, it might be this bug: [Developer tools show 200 instead of 304](https://bugs.chromium.org/p/chromium/issues/detail?id=1269602). In this case, inspect the response headers' source to confirm that the request was actually cached and did return with a `304` status code.
#### Subscriptions
We use [subscriptions](https://www.apollographql.com/docs/react/data/subscriptions/) to receive real-time updates from GraphQL API via websockets. Currently, the number of existing subscriptions is limited, you can check a list of available ones in [GraphqiQL explorer](https://gitlab.com/-/graphql-explorer)
Refer to the [Real-time widgets developer guide](../real_time.md) for a comprehensive introduction to subscriptions.
### Best Practices
#### When to use (and not use) `update` hook in mutations
Apollo Client's [`.mutate()`](https://www.apollographql.com/docs/react/api/core/ApolloClient/#ApolloClient.mutate)
method exposes an `update` hook that is invoked twice during the mutation lifecycle:
- Once at the beginning. That is, before the mutation has completed.
- Once after the mutation has completed.
You should use this hook only if you're adding or removing an item from the store
(that is, ApolloCache). If you're _updating_ an existing item, it is usually represented by
a global `id`.
In that case, presence of this `id` in your mutation query definition makes the store update
automatically. Here's an example of a typical mutation query with `id` present in it:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```1
### Testing
#### Generating the GraphQL schema
Some of our tests load the schema JSON files. To generate these files, run:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```2
You should run this task after pulling from upstream, or when rebasing your
branch. This is run automatically as part of `gdk update`.
NOTE:
If you use the RubyMine IDE, and have marked the `tmp` directory as
"Excluded", you should "Mark Directory As -> Not Excluded" for
`gitlab/tmp/tests/graphql`. This will allow the **JS GraphQL** plugin to
automatically find and index the schema.
#### Mocking Apollo Client
To test the components with Apollo operations, we need to mock an Apollo Client in our unit tests. We use [`mock-apollo-client`](https://www.npmjs.com/package/mock-apollo-client) library to mock Apollo client and [`createMockApollo` helper](https://gitlab.com/gitlab-org/gitlab/-/blob/master/spec/frontend/__helpers__/mock_apollo_helper.js) we created on top of it.
We need to inject `VueApollo` into the Vue instance by calling `Vue.use(VueApollo)`. This will install `VueApollo` globally for all the tests in the file. It is recommended to call `Vue.use(VueApollo)` just after the imports.
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```3
After this, we need to create a mocked Apollo provider:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```4
Now, we need to define an array of _handlers_ for every query or mutation. Handlers should be mock functions that return either a correct query response, or an error:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```5
When mocking resolved values, ensure the structure of the response is the same
as the actual API response. For example, root property should be `data`:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```6
When testing queries, keep in mind they are promises, so they need to be _resolved_ to render a result. Without resolving, we can check the `loading` state of the query:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```7
If we need to test a query error, we need to mock a rejected value as request handler:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```8
Mutations could be tested the same way:
```javascript
data() {
return {
// Define data properties for all apollo queries
project: null,
issues: null
}
},
apollo: {
project: {
query: getProject,
variables() {
return {
projectId: this.projectId
}
}
},
releaseName: {
query: getReleaseName,
// Without this skip, the query would run initially with `projectName: null`
// Then when `getProject` resolves, it will run again.
skip() {
return !this.project?.name
},
variables() {
return {
projectName: this.project?.name
}
}
}
}
```9
To mock multiple query response states, success and failure, Apollo Client's native retry behavior can combine with Jest's mock functions to create a series of responses. These do not need to be advanced manually, but they do need to be awaited in specific fashion.
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```0
Previously, we've used `{ mocks: { $apollo ...}}` on `mount` to test Apollo functionality. This approach is discouraged - proper `$apollo` mocking leaks a lot of implementation details to the tests. Consider replacing it with mocked Apollo provider
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```1
#### Testing subscriptions
When testing subscriptions, be aware that default behavior for subscription in `vue-apollo@4` is to re-subscribe and immediately issue new request on error (unless value of `skip` restricts us from doing that)
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```2
To avoid such infinite loops when using `vue@3` and `vue-apollo@4` consider using one-time rejections
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```3
#### Testing `@client` queries
##### Using mock resolvers
If your application contains `@client` queries, you get
the following Apollo Client warning when passing only handlers:
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```4
To fix this you should define mock `resolvers` instead of
mock `handlers`. For example, given the following `@client` query:
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```5
And its actual client-side resolvers:
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```6
We can use a **mock resolver** that returns data with the
same shape, while mock the result with a mock function:
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```7
After which, you can resolve or reject the value needed.
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```8
##### Using `cache.writeQuery`
Sometimes we want to test a `result` hook of the local query. In order to have it triggered, we need to populate a cache with correct data to be fetched with this query:
```javascript
#import "ee_else_ce/work_items/graphql/work_item_development.fragment.graphql"
query workItemDevelopment($id: WorkItemID!) {
workItem(id: $id) {
id
iid
namespace {
id
}
widgets {
... on WorkItemWidgetDevelopment {
...WorkItemDevelopmentFragment
}
}
}
}
```9
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```0
When you need to configure the mocked apollo client's caching behavior,
provide additional cache options when creating a mocked client instance and the provided options will merge with the default cache option:
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```1
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```2
## Handling errors
The GitLab GraphQL mutations have two distinct error modes: [Top-level](#top-level-errors) and [errors-as-data](#errors-as-data).
When utilising a GraphQL mutation, consider handling **both of these error modes** to ensure that the user receives the appropriate feedback when an error occurs.
### Top-level errors
These errors are located at the "top level" of a GraphQL response. These are non-recoverable errors including argument errors and syntax errors, and should not be presented directly to the user.
#### Handling top-level errors
Apollo is aware of top-level errors, so we are able to leverage Apollo's various error-handling mechanisms to handle these errors. For example, handling Promise rejections after invoking the [`mutate`](https://www.apollographql.com/docs/react/api/core/ApolloClient/#ApolloClient.mutate) method, or handling the `error` event emitted from the [`ApolloMutation`](https://apollo.vuejs.org/api/apollo-mutation.html#events) component.
Because these errors are not intended for users, error messages for top-level errors should be defined client-side.
### Errors-as-data
These errors are nested in the `data` object of a GraphQL response. These are recoverable errors that, ideally, can be presented directly to the user.
#### Handling errors-as-data
First, we must add `errors` to our mutation object:
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```3
Now, when we commit this mutation and errors occur, the response includes `errors` for us to handle:
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```4
When handling errors-as-data, use your best judgement to determine whether to present the error message in the response, or another message defined client-side, to the user.
## Usage outside of Vue
It is also possible to use GraphQL outside of Vue by directly importing
and using the default client with queries.
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```5
When [using Vuex](#using-with-vuex), disable the cache when:
- The data is being cached elsewhere
- The use case does not need caching
if the data is being cached elsewhere, or if there is no need for it for the given use case.
```javascript
#import "~/graphql_shared/fragments/user.fragment.graphql"
query workItemParticipants($fullPath: ID!, $iid: String!) {
workspace: namespace(fullPath: $fullPath) {
id
workItem(iid: $iid) {
id
widgets {
... on WorkItemWidgetParticipants {
type
participants {
nodes {
...User
}
}
}
}
}
}
}
```6
## Making initial queries early with GraphQL startup calls
To improve performance, sometimes we want to make initial GraphQL queries early. In order to do this, we can add them to **startup calls** with the following steps:
- Move all the queries you need initially in your application to `app/graphql/queries`;
- Add `__typename` property to every nested query level:
```javascript
query getPermissions($projectPath: ID!) {
project(fullPath: $projectPath) {
__typename
userPermissions {
__typename
pushCode
forkProject
createMergeRequestIn
}
}
}-
If queries contain fragments, you need to move fragments to the query file directly instead of importing them:
fragment PageInfo on PageInfo { __typename hasNextPage hasPreviousPage startCursor endCursor } query getFiles( $projectPath: ID! $path: String $ref: String! ) { project(fullPath: $projectPath) { __typename repository { __typename tree(path: $path, ref: $ref) { __typename pageInfo { ...PageInfo } } } } } } -
If the fragment is used only once, we can also remove the fragment altogether:
query getFiles( $projectPath: ID! $path: String $ref: String! ) { project(fullPath: $projectPath) { __typename repository { __typename tree(path: $path, ref: $ref) { __typename pageInfo { __typename hasNextPage hasPreviousPage startCursor endCursor } } } } } } -
Add startup calls with correct variables to the HAML file that serves as a view for your application. To add GraphQL startup calls, we use
add_page_startup_graphql_callhelper where the first parameter is a path to the query, the second one is an object containing query variables. Path to the query is relative toapp/graphql/queriesfolder: for example, if we need aapp/graphql/queries/repository/files.query.graphqlquery, the path isrepository/files.
Troubleshooting
Mocked client returns empty objects instead of mock response
If your unit test is failing because the response contains empty objects instead of mock data, add
__typename field to the mocked responses.
Alternatively, GraphQL query fixtures
automatically adds the __typename for you upon generation.
Warning about losing cache data
Sometimes you can see a warning in the console: Cache data may be lost when replacing the someProperty field of a Query object. To address this problem, either ensure all objects of SomeEntityhave an id or a custom merge function. Check section about multiple queries to resolve an issue.
- current_route_path = request.fullpath.match(/-\/tree\/[^\/]+\/(.+$)/).to_a[1]
- add_page_startup_graphql_call('repository/path_last_commit', { projectPath: @project.full_path, ref: current_ref, path: current_route_path || "" })
- add_page_startup_graphql_call('repository/permissions', { projectPath: @project.full_path })
- add_page_startup_graphql_call('repository/files', { nextPageCursor: "", pageSize: 100, projectPath: @project.full_path, ref: current_ref, path: current_route_path || "/"})